

As hands-on senior BI-experts driven by innovation, our consultants embraced SAP HANA from day one. Since 2012 we have been delivering HANA Native analytics solutions at our customers in an agile way, using the virtualisation capabilities in HANA’s data modelling to the maximum.
When heavily developing in HANA, one soon learns to be efficient, from the conceptual start onto the final delivery to the end-users.
But over the years, every HANA database will grow, with new projects, new data, on top of old datasets and naturally aging data.
While the in-memory database of HANA grows, so does its cost, because the size of your HANA’s memory footprint will impact its total cost of ownership (HANA TCO) and become a concern if neglected.
To address that concern of constant growth, there are not that many options to choose from. You can either simply buy more hot memory storage, or rework your design and programming to be even more effective, or load data off from hot memory to more cost-effective storage.
To that end, SAP has developed HANA Data Tiering solutions, currently offering several alternatives to off-load data and reduce the hot memory footprint of your dataset. The illustration below shows SAP’s depiction of the possible data tiering options in combination with the applications run on HANA.
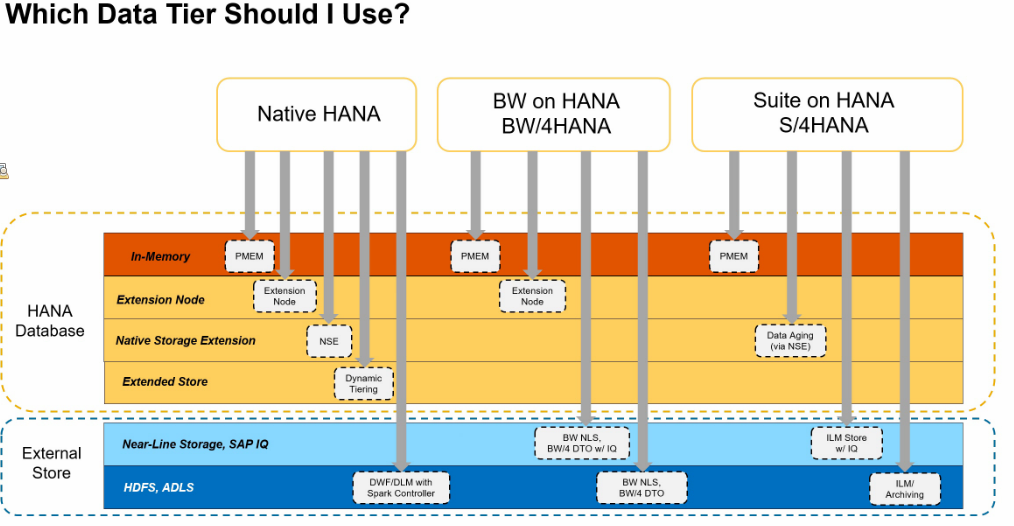
SAP HANA Data Tiering Overview (source: SAP)
Every HANA project starts with the entire database loaded in hot memory (Orange). As data grow older and are less used or less needed by the users, such data can be off-loaded to warm storage (Yellow). Data that you no longer actively use but need to keep handy, can be off-loaded to cold storage (Blue).
For the Business Intelligence solutions, you can see that both Native HANA and BW can use extension nodes for off-loading data to warm memory. In the meantime, extension nodes have proven to be a mature data tiering solution. Let us see how this type of data tiering works and can be put into practice.
From a technical perspective, extension nodes are not different from an SAP HANA hot memory node. Extension nodes are technically the same. Simply put, the difference with extension nodes and hot memory nodes lies in the way data are allocated and loaded into it. A hot node can only be loaded for 50% of its capacity with data. Thus allowing 50% room for operation and calculation to the HANA system. Extending the same type of node to warm use of data, allowed SAP to fully load it to 100% as it will not be used for any operation nor calculation by the HANA system. In practice, such a “warm extension node” can even be “over-loaded” with 200% of data… If the user would for example run a report querying warm data that are not currently loaded in the extension node, the system will swap not queried warm data out and swaps the needed warm data into memory.
From a functional perspective, using extension nodes for warm storage does not change the user experience. Reports that would run against older data that have been off-loaded to warm storage may run a fraction more slowly but won’t need any changes. On the side of underlying models and views, all can stay the same as SAP HANA will natively use the extension node in the same way as it uses a hot node and continue to recognise all objects naturally.
When using table partitioning, the following warm extension node setup illustrates the immediate advantages.

SAP HANA Extension Node Configuration
On this system, we use 2 in-memory nodes for hot memory and one node as an extension node.
The Hot nodes are loaded with 50% of hot data each, while the extension node has 200% of warm data allocated to it. For partitioned tables, we allocated the partition with the most actual and frequently used data to the hot node and the other partitions with older and less used data to the extension node, thus maximising the capacity to off-load data from hot memory without losing functionality or having to resort to new development or adaptations.
So the clear advantages of 200% data allocation, similar performance, no need for modelling changes and thus quick implementation are the gift? Well, yes, but the true gift from SAP is that an extension node costs 1/4th of a hot in-memory node.
Our customer case describes the gains of using extension nodes, freeing up to 40% of space for new data, new business users, new projects… for the same cost as the previous years.
Curious if your BW on HANA, BW/4 HANA or Native HANA landscape can save on hot memory too? To help you make sound data tiering decisions, ONE-Labs has built Oxygen for HANA, offering you insights into the warm or cold potential in your dataset and the missing visibility you need to discuss with your data owners and architects which data can effectively be off-loaded to more cost-effective warm and cold storage.
Contact us to help you build your HANA data tiering business case and make use of this true gift from SAP!
[[form id=’7262′]]